Dataset & Evaluation
RealDevBench
A comprehensive real-world development task dataset containing various application development scenarios and task types. This benchmark evaluates AI agents' capabilities across multiple dimensions of software development with automated GUI testing and interactive assessment.
Key Features
- Real-World Scenarios: Actual development challenges
- Multimodal Tasks: Text, images, audio, and data
- End-to-End Evaluation: From understanding to debugging
- Human-Aligned Assessment: 92% expert correlation
Task Type Distribution
Dataset Case Analysis
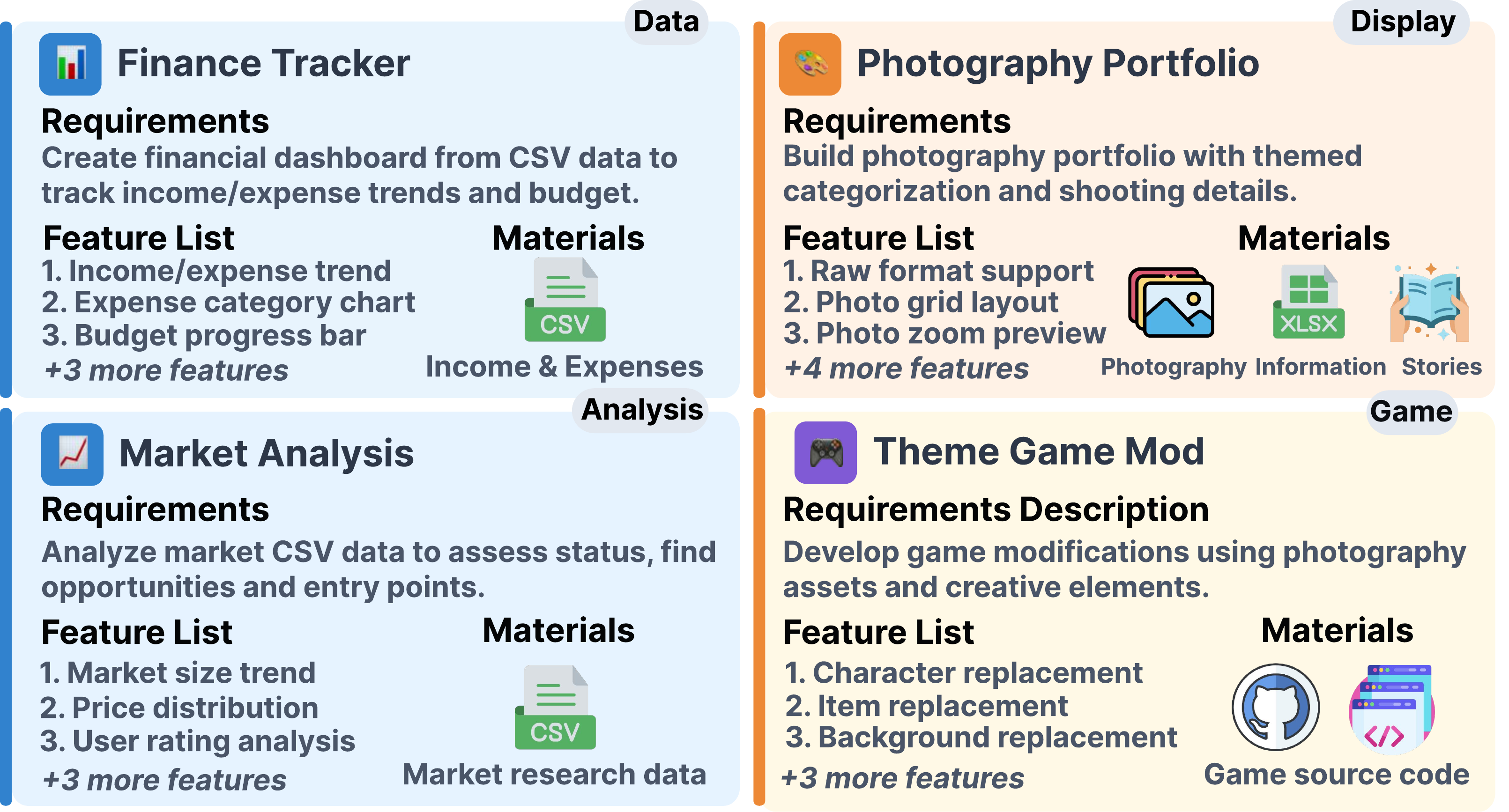
Detailed showcase of typical cases in the RealDevBench dataset, including task types, difficulty distribution, and evaluation criteria.
AppEvalPilot Framework
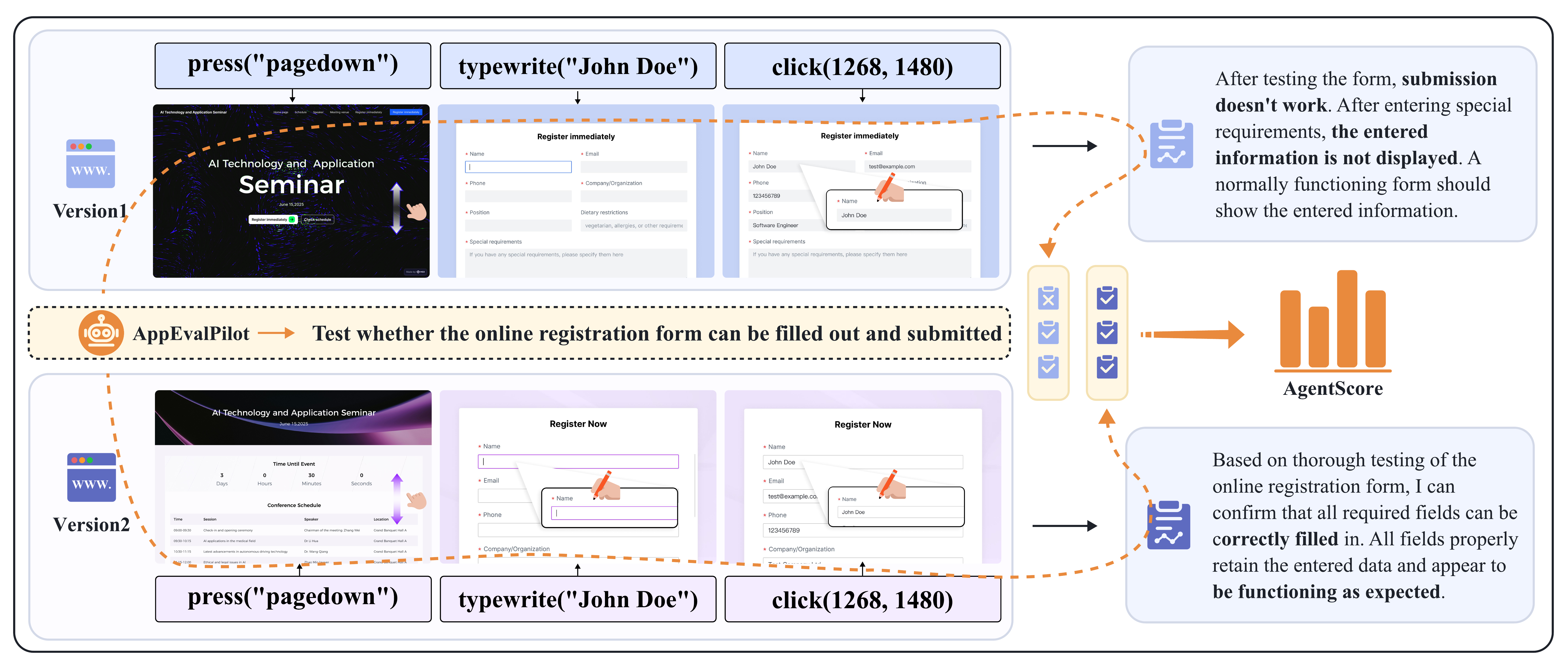
Comprehensive research methodology documentation including evaluation framework design, metric definitions, and experimental setup.
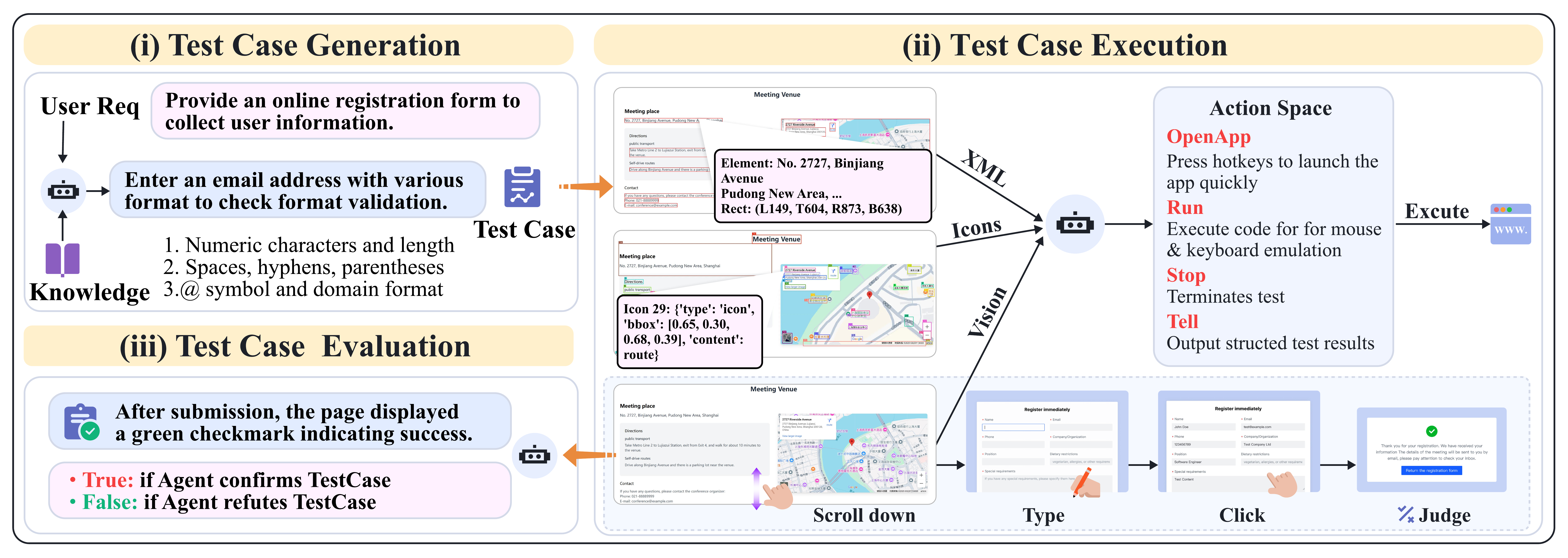
AppEvalPilot's three-stage evaluation pipeline: test case generation, interactive execution, and automated assessment with GUI interaction capabilities.
Experimental Results
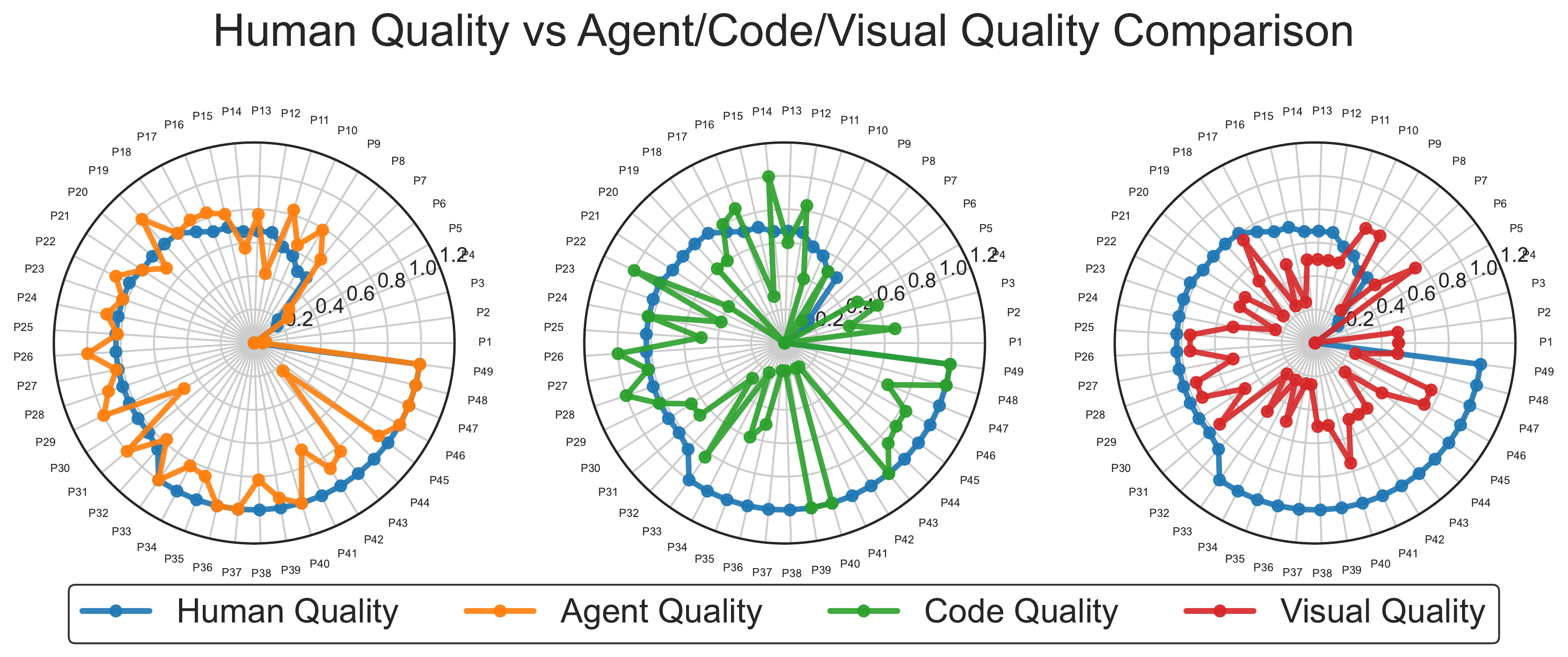
Comparative performance analysis showing different AI Agents and frameworks across multiple evaluation dimensions.
AppEvalPilot Performance Comparison
| Method | Feature-level | Test Case-level | Efficiency | ||||
|---|---|---|---|---|---|---|---|
| Quality | Align. | Quality | Align. | Acc. | Time | Cost | |
| Human | 0.74 | — | 0.65 | — | — | — | — |
| GUI Model | |||||||
| Claude-3.5-Sonnet | 0.27 | 0.23 | 0.46 | 0.49 | 0.68 | 9.20 | 1.01 |
| UI-Tars | 0.49 | 0.29 | 0.63 | 0.59 | 0.75 | 8.65 | 0.17 |
| GUI Agent Framework | |||||||
| WebVoyager (Qwen2.5) | 0.29 | 0.25 | 0.35 | 0.44 | 0.6 | 2.16 | 0.04 |
| WebVoyager (Claude) | 0.64 | 0.43 | 0.6 | 0.55 | 0.74 | 1.60 | 0.10 |
| Browser-Use (Claude) | 0.67 | 0.58 | 0.63 | 0.61 | 0.76 | 13.50 | 1.13 |
| AppEvalPilot (Claude) | 0.73 | 0.85 | 0.74 | 0.81 | 0.92 | 9.0 | 0.26 |
Performance comparison on RealDevBench benchmark. AppEvalPilot achieves superior performance with 92% accuracy and 85% human correlation, demonstrating significant improvements in evaluation quality and efficiency.